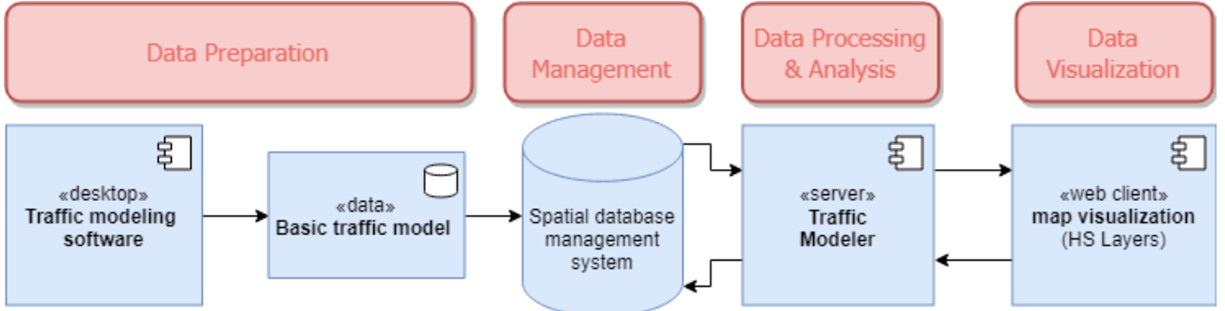
The goal of the challenge is to enable the integration of datasets provided from Citizen Observatories as well as from other citizen-science related projects and initiatives, with the NextGEOSS catalogue as an approach to connect citizen science into GEOSS.
In the context of the European Union’s Horizon 2020 research and innovation programme, four sister projects on Citizen Observatories (COs) for Environmental Monitoring (GROW, GroundTruth 2.0, LandSense and SCENT) have been launched and realised. During these projects, a variety of smart and innovative applications have been implemented, enabling citizens to be engaged with environmental monitoring during their everyday activities. The use of mobile devices and low-cost portable sensors coupled with data analytics, quality assurance and modelling approaches pave the way for citizens to have an active role and voice in environmental decision-making. The capabilities of the abovementioned tools and approaches have been demonstrated in a variety of citizen-science campaigns, being conducted across different European regions and beyond, leading to the collection of valuable environmental information. The datasets involve the following themes:
- Land cover/land use (point observations, maps, change detection validation, land use classification, in-situ validation, cropland field size and interpretations)
- Soil parameters (soil moisture, air temperature, levels of light); Planting and harvesting dates
- Water parameters (water level, water velocity)
- Air quality parameters (black carbon concentration)
- Phenological observations (species and pheno-phase identification)
- Disaster resilience (maps and time series data related to flood monitoring)
- Urban green space quality (users’ perception through the provision of responses to questionnaires and images)
The datasets are being managed by different infrastructures involving various access endpoints as well as the utilisation of OGC standards (i.e. WMS, WGS, SOS, etc), while at the same being accompanied by dedicated metadata.
Thus in order to facilitate the metadata ingestion in the NextGEOSS catalogue, continuously running harvesters (for the Data Sources which have new Data available daily) and on-demand harvesters (for static collections of Data) shall be implemented.
Yes, I want to register for Challenge #7!
————–
Data Cataloguing in NextGEOSS
One of the offers available in NextGEOSS is the Data Cataloguing. Catalogue data in NextGEOSS can bring some benefits such as:
- Your Data will be EASILY DISCOVERABLE and REACHABLE to a wider audience like the entire GEO Community through the NextGEOSS catalogue;
- Original Data Sources and Data Providers will be more visible. On the NextGEOSS catalogue there is a page listing all the Data Providers;
- Easy access to input Data to be automatically ingested by applications due to the OpenSearch interface which allows to find the datasets catalogued and the enclosure links to where the real Data is;
- Data catalogued in the NextGEOSS Catalogue can be used by the scientific communities in their applications;
NextGEOSS Catalogue does not store data. Only metadata and download links to where the real data is stored (enclosure links) are catalogued. The metadata ingestion in the NextGEOSS catalogue is quite flexible since it is possible to harvest metadata from different interfaces such as OpenSearch, CSW, WFS, CKAN API, REST API, OAI-PMH and others. Also different types of Data Connectors, depending on the frequency of the Data publication on the original Data Sources, can be built:
- Continuously running harvesters (for the Data Sources which have new Data available daily)
- On Demand Harvesters (for static collections of Data)
NextGEOSS Harvesters have also recovering mechanisms to deal with possible failures that may happen on the data catalogue or on the original data source. For example, if the original data source is down for some time, as soon as it is available again, the harvester will restart the harvesting process from the last dataset harvested and will ensure that no data is missing.
To be possible to catalogue metadata in the NextGEOSS Catalogue, there are some requirements that must be fulfilled by the data Provider:
- A queryable API or interface to access the metadata in the original data source is required (OpenSearch, CSW, REST API, etc.);
- The access to the original metadata records following a methodically approach is required (for example temporal queries);
- The metadata fields in the original data source must be clear and, ideally, follow a metadata standard;
- To have a clear understanding about how often the data is published in the original Data Source (frequency), different product types and if the data belongs to any area of study (such as Agriculture, Marine, Food Security or others);
- Data Provider must keep the real data available for a considerable time period to ensure that the links to the original data on NextGEOSS Catalogue are not broken links;
- To have a good availability and short response times when querying the original data source;
All of these requirements are considered during the feasibility analysis performed by the development team. If the requirements are fulfilled, it will be possible to build the data connector (harvester) which, after a set of tests in a staging instance of the catalogue, will be deployed in production.
Main obstacles to build data connectors:
- Complex metadata and/or not following any specific standard. Difficult to map the metadata fields;
- Metadata with many repeated fields and repeated information. Additional metadata filters. needed;
- Limited APIs and interfaces which do not allow to perform methodical queries and organize the metadata records;
- Metadata or interfaces that are not mature enough since they are still being updated;
- Unstable data sources and long response time to queries;
- Short retention period of the real data on the data provider;Data sources that do not provide links to the real Data within the metadata making it impossible to have enclosure links to the real data on NextGEOSS catalogue;